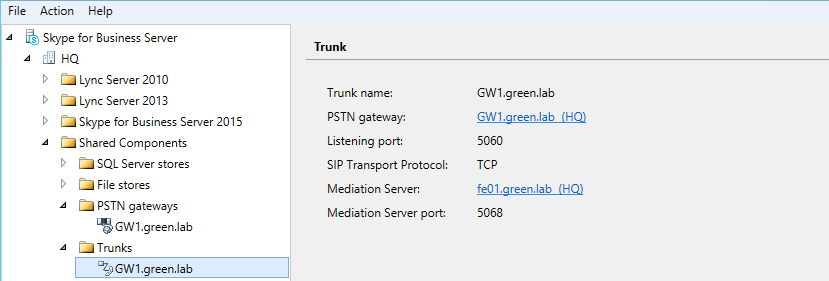
If you need to implement Site Based policies in Teams, there are several pre-requisites and design decisions that you need to be aware of and consider in your design.
If you are in Canada, the United States, or India then this absolutely applies to you. If you are in any other location, it probably applies to you unless you are a very small Teams deployment in a single office.
Here’s a list of the site based policies in Teams:
- Location Based Routing
- Emergency Call Routing Policy
- Emergency Calling Policy
- Local Media Optimization
- Roaming Policies
Location Based Routing
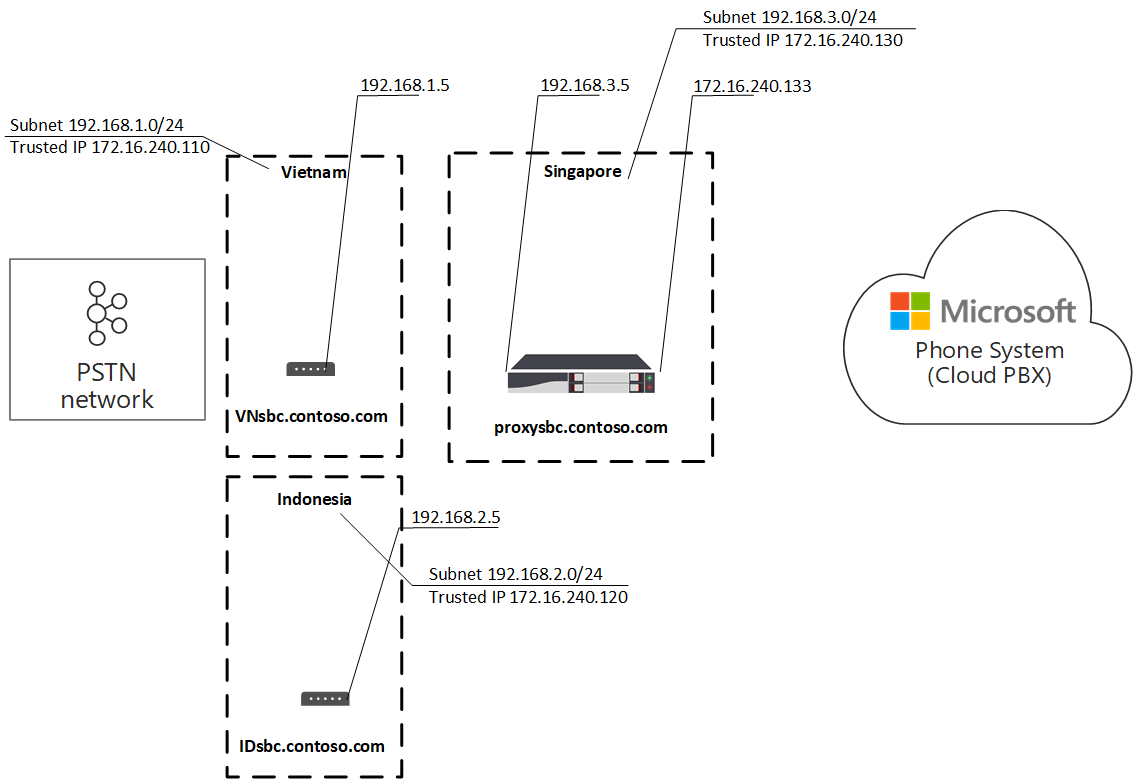
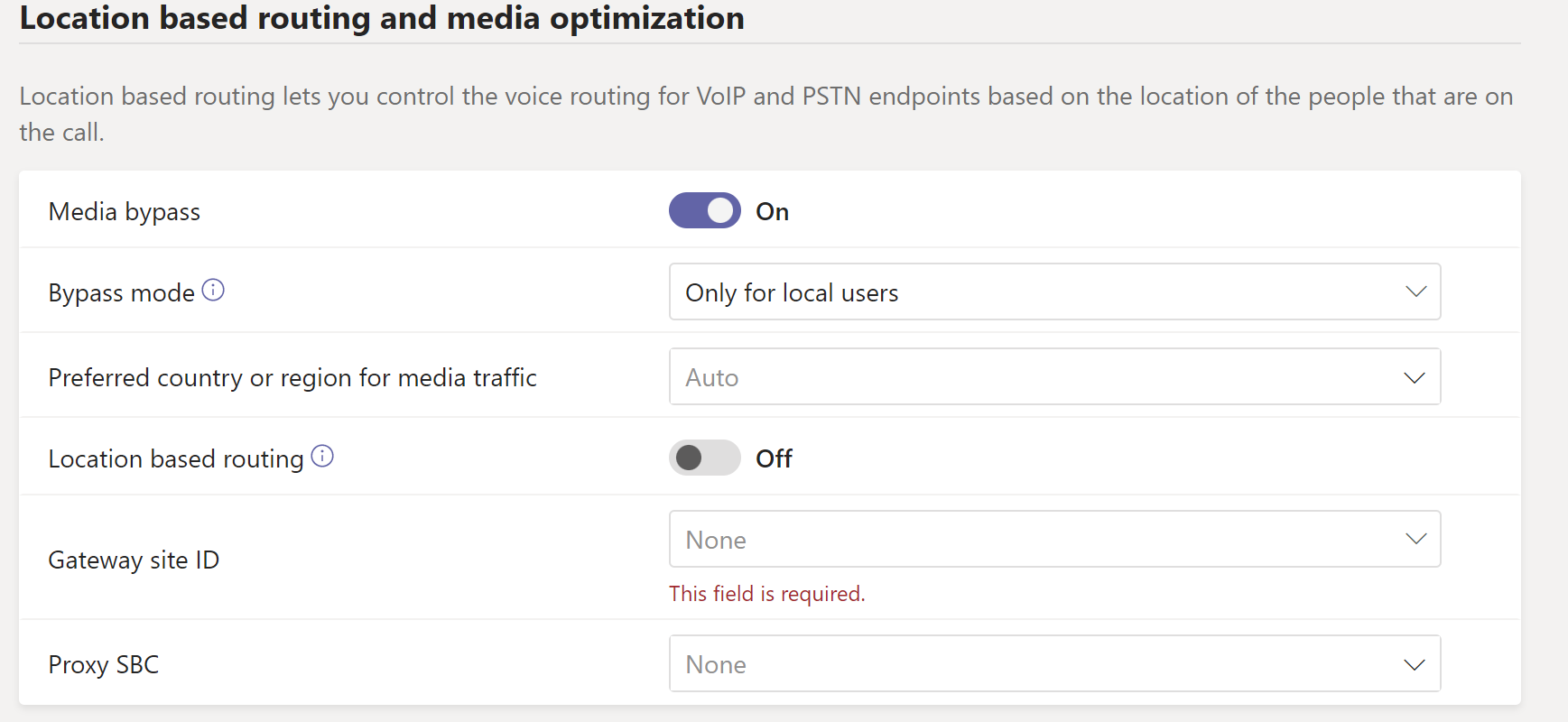
Location Based Routing is mostly used in India, though there are a few other scenarios where it may be useful. The general idea here is that you can’t mix IP based calls/meetings with more than one PSTN site.
Emergency Call Routing Policy
This policy controls where Teams will route emergency calls to when using dynamic emergency calling for Direct Routing and Operator Connect scenarios. You use dynamic emergency calling in Canada and the US by law, and it make sense to me to use it in other locations as well.
Emergency Calling Policy
This should really be called the Emergency Call Notification Policy. When an emergency call is placed from a site, this policy controls who is notified via IM, who is conferences in by phone, and whether the phone call is muted or unmuted (you should ALWAYS configure muted, you do not want to interfer with the emergency call taker getting the information they require).
Also tucked into this policy is “External location lookup mode”. I have yet to establish why this feature is in this policy. The External location lookup mode turns on the “work from home” location experience for mobiles and computers, to user the device’s native location services and/or user input to establish a location for emergency calls. If you have the network information for this policy to kick in for a site, you also have the network information to dynamically establish the caller’s location. Realistically, you need to turn on the External location lookup mode in an Emergency Calling Policy that is assigned to the user, so that it triggers when they’re outside of your organization. (Note: there is currently a bug where if you set the External location lookup mode on a global Emergency Calling Policy, it does not work. You need to assign the policy to each user individually).
Local Media Optimization
LMO allows a client device to send media directly to the inside interface of an SBC, avoid travelling up to Teams and back down. The previous couple of posts here cover LMO.
Roaming Policies
Here’s another policy name that doesn’t make sense to me. Roaming Policies apply bandwidth restrictions to users that are present in a site, replacing the same two parameters that are in the policy that is assigned to the user. In the SfB world, this was called Call Admission Control, and was handled in an entirely different fashion.
Requirements
The requirements for these site based policies to trigger are:
First, the client must egress to the Internet that is static, and dedicated to the organization. This is generally the IPv4 address that the client NATs to, but it could be an IPv6 address or an IPv4 address assigned to the device that isn’t NAT’d. These addresses are called Trusted IPs.
Second, you must define a Network Site under Locations > Network Topology and assign the subnets in use at this site to the Network Site.
Constraints
There are some technical constraints to these requirements.
For the Trusted IPs, static means that the IP address(es) do not change. A DHCP assigned address with a reservation is okay. If the address were to change, you would a way to be notified of this change, then you’ve have to update this information in Teams, then policies would have to replicate and be pulled by clients. That’s no good for emergency calling, and isn’t that great for other scenarios either.
Also for the Trusted IPs, dedicated to the organization means that you can’t use cloud proxy/firewall services such as those provided by zScaler, and the address could be shared between multiple organizations and the address(es) assigned to your clients may change.
For the Network Sites, the subnets must be assigned to only one site. You cannot have a subnet assigned to or spanning multiple sites. If you need your sites to be more granular that your subnets permit, you will need to resubnet. A typical place this happens is with centralized wifi controllers that lay one very large subnet over an entire organization.
There is also a large design constraint to be aware of. These five policies (above) are typically assigned to sites. You define the site, then assign the policies to the site. You do not get to define different sites for different policy types.
Let’s use an example to clarify that. A university campus has several buildings in a campus, and you’d like to set the same LMO policy and Emergency Call Routing policy to the entire campus. That makes sense, the whole campus is probably served by the same PSTN service, and likely needs to send all emergency calls to the same spot. Plus, the university has a wifi system that uses a large /20 subnet for the entire campus. You can define the entire campus as one site and meet these objectives (sorry for making this sound like a certification exam!)
However, in the US Kari’s law states that you must notify someone within the building with the details of any emergency call from that building. You need one Emergency Calling Policy for each building. This means that you must define each building as a site, and you must break the wifi subnet up into smaller subnets that only belong to one building. You don’t need multiple Emergency Call Routing policies though, you can assign the same “campus” policy to each site.
This type of scenario makes network engineers scream, and threatens to delay the project until they can sort the wifi. As an interim measure, I have seen some organizations configure each building as a site and assign the wired subnets to them. They then assign the giant wifi subnet to a “campus wifi” site, and configure an Emergency Calling Policy to notify staff who can relay the notification information to the appropriate parties. Don’t make a decision to do this on your own, you are not a lawyer (probably). Give this decision to your legal/risk/executives to deal with.