
Perhaps the most time consuming portion of the Teams voice projects that I’m involved in relates to location… A Teams user’s location can be used for emergency calling, bandwidth consumption over constricted WAN or internet links, or things like location based routing and local media optimization.
One of the first questions I ask is: “Do you have subnets that span multiple buildings, especially for wifi”. For emergency calling, each building or facility may need to be broken up into “dispatchable locations” if you’re reading legislation or “places” in Teams lingo. Essentially, if you’re a large building like a school or factory, how do the first responders find you? That’s your “emergency response location” or your “place”. You’ll need a network characteristic to establish which place a Teams client is in. That could be subnet, the switch chassis ID, or the switch port on that switch you are connected to, or it could be the BSSID, which reflects which access point you’re connected to.
If you have IP subnets that span buildings, you will need to re-subnet in order to get the proper physical granularity that’s needed for location-based functions in Teams. There are a couple of exceptions to this.
First, if the only spanned subnets you have are for server/storage infrastructure, you’re fine. Just ensure that phones can’t be plugged into this network (which you should be doing anyway!), especially a server room phone.
The second exception would be if you don’t need any Network Site based policies other than Emergency Calling Policy. This is the one that notifies someone at the facility that an emergency call has been placed. In the US, the FCC website says (this is Kari’s law):
“When a 911 call is placed on a MLTS system, the system must be configured to notify a central location on-site or off-site where someone is likely to see or hear the notification.”
From https://www.fcc.gov/mlts-911-requirements
Typically, you would need to notify someone at that site about the emergency call, and “that site” has IP subnets associated with it, and an Emergency Calling Policy associated with it. The Emergency Calling Policy handles the notifications, so if a subnet spans multiple sites, you can see how this makes it impossible to notify someone only at the site from which the call was placed.
There are two options or scenarios here. The first is one in which you can notify parties at both/all sites, and train them how to tell when a call is from their site, and to take appropriate action. The second would be when you have something like a central security desk that can be notified, and that security desk can then take appropriate action – commonly this is facilitating first responder access to the building, but it could also be first aid or security teams responding to the incident.
A university campus is an example of a site where I common encounter IP subnets that span sites/buildings/facilities. It’s also a great example of a site where this many not matter, and every university that I’ve encountered has security and/or police departments who can handle responses to these notifications.
An example of where things don’t work with spanned subnets would be a wifi subnet that spans the facilities for a municipality that doesn’t have a security desk (though they may have some “in charge” of security). A call to emergency services from a library would need to notify someone at the library, and not HR, IT or city hall reception. This isn’t so much because they couldn’t in turn notify someone else at the library to take action. My concern here would mainly be around availability and hours of work. If the library is open until 9pm and HR, IT, and city hall are all closed, you’re not notifying anyone.
In a case like this, I would recommend the city to re-subnet their wifi. In some cases, depending on their wifi controller(s), this could be a painful exercise, as some wifi controllers cannot have a single SSID (which is desirable) across the organization use a different subnet at each location. Instead, one SSID would need to be created per location, and then all of the wifi clients at that location would need to have their wireless connections updated to the new SSID. That’s no fun but is necessary in many cases to properly meet emergency calling legislation, or to use other location-based policies like Network Roaming (WAN/Internet bandwidth consumption limits for Teams, based on the site).


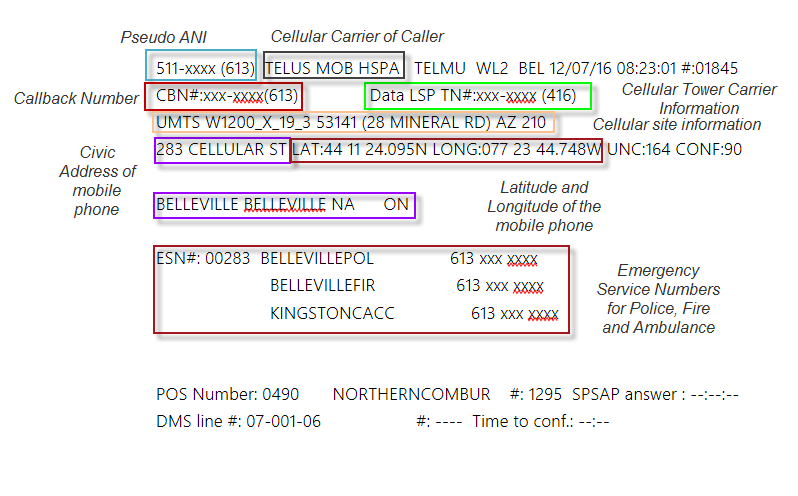 Next up, we’ll have a look at how VoIP Systems can use 3rd party “next generation” services and ugly workarounds to also provide location information to PSAPs.
Next up, we’ll have a look at how VoIP Systems can use 3rd party “next generation” services and ugly workarounds to also provide location information to PSAPs.